 En
En
 Es
Es
This is the documentation for the deprecated product VMmanager 5. It is no longer updated and may be irrelevant. Documentation for the current version of VMmanager can be found in the VMmanager 6 section.
Issues with control panel
How to upgrade VMmanager KVM to VMmanager Cloud.
This operation is not supported.
VMmanager is freezing and running slow, "too many connections" error is shown in the log
The possible cause of the issue: libvirt is freezing. Make sure that libvirt is accessible; restart it if needed.
What processes are important for VMmanager? What can I monitor?
The ihttpd process is very important. You also need to make sure that libvirt is up and running on serves.
What units of measure are used in a control panel?
The control panel uses KiB and MiB
- KiB (kibibyte) 210= 1024;
- MiB (mebibyte) 220 = 1048576.
How do they differ from KB and MB?:
- MB (megabyte) 106 = 1000000;
- KB (kilobyte) 103 = 1000.
How to create a virtual machine using MB and GB:
- If you want to create a virtual machine with 2Gb of RAM, enter 1907MiB in the VM creation form (the more exact value is 2GB = 1907,35MiB);
- If you want to create a virtual machine with 15GB of HDD, enter 14305Mib;
- How to calculate units of measure.
Issues with cluster nodes
After you have added the virtual machine, one of the cluster nodes gets inaccessible. When trying to connect to it via SSL, you can connect to the virtual machine
When allocating IP addresses to virtual machines from the same network, IP addresses for cluster nodes are allocated from, the system may allocate the IP address that is already assigned to the cluster node, therefore the node will become accessible. To avoid this, reserve IP addresses of cluster nodes in the local IP pool or in IPmanager if your system is integrated with this panel.
To release an IP address of the virtual machine, assign a new IP to the VM. Navigate to "Management" → "Virtual machines" → select a virtual machine → open the "IP address" tab. Add a new IP and delete the IP address that overlaps the cluster node IP. Change the settings of the network interface so that the virtual machine can work with the new IP and restart the network with the following command:
When you add a cluster node: Error installing the packages 'vmmanager-kvm-pkg-vmnode' on the remote server. For additional information, please refer to the control panel log"
Cause: libguestfs can be installed only in the interactive regime.
Solution: install the package vmmanager-kvm-pkg-vmnode from the console.
Cannot add a node with CentOS
A possible cause of the issues: the required packages cannot be installed. The cause of the issue - the epel repository is not connected. Possible cause: incorrect server time - the repository cannot be found. Correct the server time, if needed, and try again.
Cannot add a new node: "Cannot apply the Firewall rules: error in iptables rules
In vmmgr.log you can see that the system could not start the /etc/libvirt/hooks/firewall.sh script
# /etc/libvirt/hooks/firewall.sh
# Generated by VMmanager KVM on Sat Apr 18 21:31:18 CEST 2015 *filter
# ISPsystem firewall rules
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPT
-F INPUT
-F FORWARD
COMMIT --------------------------------
ip6tables-restore v1.4.7: ip6tables-restore: unable to initialize table 'filter'
Error occurred at line: 2
Try 'ip6tables-restore -h' or 'ip6tables-restore --help' for more information.You need to comment records in /etc/modprobe.d/ipv6.conf, and restart the ipv6 module.
Utilities for cluster management
Execute the command on all cluster nodes:
/usr/local/mgr5/sbin/nodectl --op exec --target all --cmd 'echo "Hello, world!"'Access the cluster node via SSH:
/usr/local/mgr5/sbin/nodectl login <cluster node id>View a list of cluster nodes:
/usr/local/mgr5/sbin/nodectl listChange the master-node (server priorities will be changed as well and VMmanager will be started on the selected server):
/usr/local/mgr5/sbin/cloudctl -c relocate -m <cluster node id> Recovery of virtual machines in VMmanager Cloud
How to restore virtual machines
If a cluster node fails, the virtual machines running on that node will be recovered on an available node. Virtual disks of virtual machines must locate in the network storages. If the VM disk was located in local storage, the virtual machine won't be restored, as its data become inaccessible.
Virtual machines will be recovered on running cluster nodes right after the cluster node fails. The recovery process includes the following steps:
- The system selects a cluster node where the virtual machine will be created Distribution of virtual machines on cluster nodes;
- Creates the virtual machine with the same parameters as on the failed node;
- Connects the network disk of the machine and restarts it.
The recovery process is logged into the VMmanager log vmmgr.log. The following is the information in the log during the restore operation:
Restore vm $idHow to restore a cluster node
A cluster node is considered failed and is disconnected from the cluster if it does not respond for more than 1 second. Please note: the server reboot takes a longer time. Take into account that you will need to restore the cluster node after reboot. You must not reboot the cluster node simultaneously so that their number is less than the quorum.
When the cluster node becomes inaccessible corolistener changes the configuration file on all the running nodes. To restore the node, complete the following steps:
- Make sure that all the services on the node are up and running;
- Add the cluster node into the quorum Cluster node→ Cluster nodes→ Join;
- Synchronize the corosync configuration file with other nodes:
/usr/local/mgr5/sbin/mgrctl -m vmmgr cloud.conf.rebuild- start corosync:
/etc/init.d/corosync start- start corolistener:
/usr/local/mgr5/sbin/corolistener -c startHow to restore a cluster after the quorum is lost
VMmanager Cloud is replicated on all the cluster nodes to ensure fault-tolerance of the control panel. VMmanager starts only on one cluster node. After the quorum is lost, it may happen that VMmanager cannot start on a cluster node even with the largest priority.
Cluster restore mechanism:
- Perform the following operations on the master node:
a. Delete the Option ClusterEnabled option from the /usr/local/mgr5/etc/vmmgr.conf file;
b. Make sure the /tmp/.lock.vmmgr.service file is present. Create the file if it is not specified:
touch /tmp/.lock.vmmgr.servicec. Add the license IP address to the interface vmbr0:
ip addr add <IP address> dev vmbr02. Perform the following operations on the cluster nodes:
a. Make sure the /usr/local/mgr5/var/disable file is present. Create the file if it is not specified:
touch /usr/local/mgr5/var/disable
b. Make sure the /tmp/.lock.vmmgr.service file is not present. Delete it if needed:
rm /tmp/.lock.vmmgr.servicec. Make sure the license IP address is not present on the interface vmbr0.
d. Restart the control panel;
e. Enable the cloud function in the control panel
Issues with storages
Issues with network LVM-storage
Cannot create an LVM storage. When trying to add a new cluster node, you may get the error: "unsupported configuration: cannot find any matching source devices for logical volume group".
Make sure that the LVM commands show that physical volumes that we want to add, exist, and the storage is up and running. Solution: try to add the storage and cluster node:
virsh pool-undefine storage name.Issues with network LVM-storage
Cannot find the group volume on cluster nodes
If the vgs command on the cluster nodes doesn't display the LVM volume group from the iSCSI-storage, make sure that iscsi-target works with it. Execute the following command:
tgtadm -m target --op showIf the section is missing in the lun list, you should add it manually:
tgtadm -m logicalunit --op new --tid 1 -b /dev/sda2 --lun 1Restart tgtd, connect the cluster nodes to the target and execute pvscan to detect the pool.
Error adding a new cluster node
After you have edited the /etc/tgt/targets.conf file (for example, you need to connect a new cluster node, and one more initiator-address was added), the cluster node cannot be connected (the 'iscsiadm -m discovery -t st -p ...' command returns iscsiadm: No portals found). A possible cause of this issue: the service cannot restart and does not re-read the configuration file while clients are connected.
Make sure the service has been restarted:
service tgtd stop
killall -9 tgtd
service tgtd startIssues with iSCSI-storage
The requested operation is not valid: the storage pool is not active
This error occurs in case of problems with the iSCSI storage. Make sure the tgtd service is running on the server with storage. If the error occurs when adding a new node, access the node via ssh and execute:
virsh pool-list --allIf you see iSCSI-UGLY_004 not active yes, try deleting the storage and add a new node once again:
virsh pool-undefine iSCSI-UGLY_004internal error Child process (/sbin/iscsiadm --mode discovery --type sendtargets --portal xxx.xxx.xxx.xxx:3260,1) status unexpected: exit status 255
VMmanager cannot connect to the server with iscsi using port 3260. Possible causes of this issue:
1. Disable SeLinux
2. The required port is denied by the firewall settings.
"operation failed: Storage source conflict with pool: '...' "
The cause of the error: the dir or netfs storages already exists on the server, and it is located in the same directory, where you are trying to create a new storage.
Solution: Delete the existing storage on all the cluster nodes:
virsh pool-list
virsh pool-dumpxml <pool-name>
virsh pool-destroy <pool-name>
virsh pool-undefine <pool-name>Issues with RBD-storage
Cannot add a storage to the cluster node
ceph auth get-or-create client.vmmgr mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=isptest' key for client.vmmgr exists but cap osd does not matchSolution: Log in to the monitor and delete the client.vmmgr user
ceph auth del client.vmmgrChange IP-address of the Ceph-monitor
For newly created virtual machines:
On the Ceph-monitor an administrator of the ceph-storage can change the IP address. In MySQL vmmgr on the master VMmanager in the metapool pool you need to change thesrchostname field into a new node. In rbdmonitor table make sure "metapool" corresponds to "id" from the metapool table. Clear cache:
rm -rf /usr/local/mgr5/var/.db.cache.vm*and restart the panel
killall coreExecute the following commands for the existing virtual machines:
sed -i 's/old_IP/new_IP/g' /etc/libvirt/qemu/*.xml
virsh define /etc/libvirt/qemu/*.xmlIssues with GlusterFS-storage
When locating two different VMmanager storages (QCOW2 and RAW) on the same GlusterFS volume and directory, cannot move the virtual disk between these storages
Use different directories on the network storage.
Cannot import virtual machines from VMmanager or libvirt directly to GlusterFS, as the libvirt driver doesn't record disk content from the thread.
Use other types of storages, then move disks of imported machines into GlusterFS.
Issues with NFS-storage
Cannot create a virtual disk
libvirt cannot create a virtual disk in the network storage. In the log you can see the following information:
rpc.idmapd[706]: nss_getpwnam: name 'root@testers' does not map into domain 'ispsystem.net'.To resolve the issue specify the correct "Domain" parameter in the /etc/idmapd.conf file on the server and client. Restart the server and client once completed, and add the storage again to VMmanager.
Error deleting data from storage
Cannot delete disks created in the NFS storage: libvirt error when executing "VolDelete": "cannot unlink file '/nfs-pool/volume': Permission denied"
In /var/log/messages you can see the following information:
Sep 16 13:11:07 client nfsidmap[7340]: nss_getpwnam: name 'www-data@lan' does not map into domain 'localdomain'To resolve the issue specify the correct "Domain" parameter in the /etc/idmapd.conf file on the server and client. Restart the server and client once completed, and add the storage again to VMmanager.
Issues with virtual disks
libvirt error when modifying disk space
libvirt error when executing the "Grow" operation: "unknown procedure: 260"
This error occurs if you are using older versions of libvirt. To resolve the issue, update libvirt.
Failed to mount VM disks" after password change
This error occurs when trying to change the password of a virtual machine running the XFS file system located on an ext4 host server, kernel version 3.10 and later. Execute
guestmount -v -x -a <disk_image> -i <path to the mounting point>"mount: wrong fs type, bad option, bad superblock" means that the virtual machine cannot run with libguestfs.
Cause of the issue: guest xfs is not fully supported by the RHEL/CentOS 6 kernel. For more information, please refer to virt-inspector can't obtain info from rhel7.3 guest image on rhel6.9 host. Unfortunately, libguestfs developers say that this bug cannot be resolved.
Network issues
IPv6 on Ubuntu 12.04
The following error occurs when adding the IPv6 cluster node: "Unable to connect to the XXX server. SSH or libvirt-bin might not be running"
Information in the log:
Mar 13 13:26:09 [2157:0x95E700] virt TRACE ErrorCallback libvirt error code=38 message=Cannot recv data: ssh: external/libcrypto.so.1.0.0: no version information available (required by ssh) : Connection reset by peertname [2a01:230:2:3::3]: Name or service not known
Mar 13 13:26:09 [2157:0x95E700] virt DEBUG vir_host.cpp:70 Connect to qemu+ssh://[2a01:230:2:3::3]/system?keyfile=etc/ssh_id_rsa
Mar 13 13:26:09 [2157:0x95E700] err ERROR Error: Type: 'vir_connection'
Mar 13 13:26:09 [2157:0x95E700] virt TRACE Fail libvirt message: 'Cannot recv data: ssh: external/libcrypto.so.1.0.0: no version information available (required by ssh)This error occurs on Ubuntu 12.04. Learn more
Solution: Add the IPv4 cluster node.
Issues with virtual machines
Error creating a virtual machine: "ERROR: Exception 1: Insufficient RAM for VM creation", therefore Swap has sufficient RAM
Free RAM = free + cached. Swap is not counted.
Cannot create a virtual machine. libvirt returns the error when executing "Start": "internal error Process exited while reading console log output: qemu-kvm: -chardev pty,id=charserial0: Failed to create chardev"
To resolve the issue, execute
mount -n -t devpts -o remount,mode=0620,gid=5 devpts /dev/ptsCannot create a virtual machine. libvirt returns the error when executing "Start": "Start": "internal error cannot create rule since ebtables tool is missing"
Check the lsmod |grep ebt command output. If it doesn't return any data, ebtables is not supported by the kernel. You will need to recompile the kernel, or download another one and change the boot priority by modifying grub.conf.
OS installation issues
The installer cannot download the response file
This error may occur when trying to connect to a virtual machine via VNC.
Possible causes:
- IP-address of the virtual machine cannot be bound to the cluster node where the machine is created. This may happen if, for example, IP addresses in a data-center are bound to MAC-addresses;
- The resolver on the virtual machine doesn't work. The first resolver from the parent server (the /etc/resolv.conf file) is specified;
- VMmanager is trying to send the response file through the internal IP address which is not accessible from the outside, and the installer downloads the response file via the external network;
- Redirect for http-connection is set up in the ihttpd configuration file.
VMmanager receives the IP address where the response file will be sent, from ihttpd. Execute the command to find it:
/usr/local/mgr5/sbin/ihttpdThe system will take the first IP from the list that meets protocol requirements. If the command shows an internal IP address as the first one, the installer won't get the response file. Configure ihttpd, mark the external IP address as the first one.
Cannot receive the full preseed-file when installing Debian
Delete the "nocunked" option in the ihttpd - /usr/local/mgr5/etc/ihttpd.conf configuration file.
Restart ihttpd.
Cannot install Windows 2016 on the virtual machine: In VNC you can see that the boot process freezes
This error occurs on servers with QEMU 1.5, 0.12, 1.1.2.
Solution: when creating a virtual machine enable the host-passthrough CPU emulation mode. If QEMU 2.6 is used, you don't need to change the emulation mode to install the templates, however you may need to restart libvirt (service libvirtd restart) (if the system was updated).
The following errors may occur when installing FreeBSD-amd64 on certain types of processors:
- the installation process hangs;;
- In VNC you can see something like this:
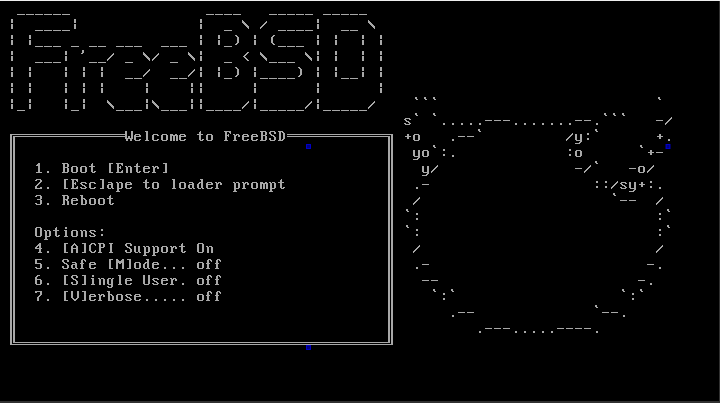
-
-
- Pressing the buttons has no effect;
-
In such cases, we recommend using FreeBSDx32 images. You can also install http://elrepo.org/tiki/kernel-lt.
Virtual machines not accessible
A virtual machine is not accessible after the reboot
Make sure that:
- The cluster nodes can connect to the master server.
- vmwatch-master on the master server listens to the correct IP address (which is defined by the VmwatchListenIp parameters of the VMmanager configuration file). If the IP is not specified, the system will use the IP of the connected local cluster node. To apply the changes restart the reconfiguration of the services:
/usr/local/mgr5/sbin/mgrctl -m vmmgr vmwatch.configureVM migration issues
Live migration error: virt TRACE ErrorCallback libvirt error code=38 message=Unable to read from monitor: Connection reset by peer
This error occurs in some configurations with libvirt 0.9.12.3 if you select "virtio" as a VM network interface. For the successful migration, in the VM network interface, you need to specify a different network device mode, for example, "e1000". If you want to change this parameter for existing virtual machines, you will need to restart it.
Internal error: unable to execute QEMU command 'migrate': this feature or command is not currently supported
This error occurs when trying to migrate a running virtual machine on CentOS 7 cluster due to the QEMU bug on CentOS 7
Possible solutions:
- Suspend a virtual machine and them migrate
- Set up QEMU from the RedHat repository
All commands are performed with root permissions in the console for every cluster node
yum install centos-release-qemu-ev yum updateAll the installed packages will be updated (if new updates are available for them). In the list of packages the following data can be found:
libcacard-ev
qemu-img-ev
qemu-kvm-common-ev
qemu-kvm-ev
qemu-kvm-tools-evAfter QEMU/KVM is updated, restart virtual machines and libvirtd.
To move a VM between two VMmanager, add the source server as a new node in new VMmanager and move the virtual machine using VMmanager tools.
Cannot migrate and back up virtual machines with qcow2 disks on servers running QEMU 2.6
Versions: QEMU 2.6, libvirt 2.0.
This is the bug QEMU 2.6, which was fixed in QEMU 2.7.
Solution:
- Restart the virtual machine;
- Update QEMU to 2.7. This variant has not been tested yet, and we cannot guarantee it will help. You can use it at your own risk.
LVM disk size is increasing during VM migration
This is the QEMU bug: https://bugs.launchpad.net/qemu/+bug/1449687 https://bugzilla.redhat.com/show_bug.cgi?id=1219541
You can fix it only in QEMU. There are two variants: migrate the suspended virtual machine and use qemu-img convert after migration for disk compression.
"Attempt to migrate guest to the same host".
VM migration failed and var/migratevm.log contains the above error. Possible causes:
- All of the cluster nodes have the same hostname. Solution: modify hostname. Edit the/etc/hostname and /etc/hosts files, change the old hostname into a new one.
- The cluster nodes have the same product_uuid. Run the command on all cluster nodes:
cat /sys/class/dmi/id/product_uuidIf their values coincide, you may use the following solution: edit the /etc/libvirt/libvirtd.conf file for the cluster nodes having the same product_uuid. Locate and comment out
#host_uuid = "00000000-0000-0000-0000-000000000000"Specify the host_uuid value. It must not contain the same digits. Restart Libvirt
libvirt failed while executing the "Define" operation: "unknown OS type hvm"
Reboot the server. If the problem persists, 1. Make sure that the virtualization is on in BIOS.
modprobe kvme
grep '^flags.*(vmx|svm)' /proc/cpuinfoNo response means it is disabled and you should enable it.
Cannot migrate the virtual machine <vm name>: the backup process in progress
If the backup process is running in the control panel and the virtual machine is in the list for backup, all the operations with such a machine will be blocked unless the backup process is over.
VM import issues
ERROR Error: Type: 'host_missing' Object: Value: during import
This error means that the cluster node for import is not found. Make sure that the storage that you have selected for import has enough disk space and RAM for creating a virtual machine.
ERROR Error: Type: 'xml' Object: 'parse_file' Value: '/nfsshare/metainfo.xml' during import
To resolve the issue, create the file /nfsshare/metainfo.xml. Copy its content from metainfo.xml of any OS template.