

My name is Alexander Grishin, and I am the product manager of the VMmanager virtualization platform. We have recently released autonomous unbreakable clusters allowing you to set up an infrastructure of high availability and continuity of business processes of the company. If one of the physical servers in a high availability cluster fails, the virtual machines will be recovered on a healthy node, automatically and with minimal downtime.
During the implementation, we took into account the experience of the previous version of our product - VMmanager Cloud - and studied the best practices of competitors, such as Proxmox, OpenStack, VMware and others. Let me tell you how high availability works "under the hood”

Glossary
Vocabulary
A node is a physical server with an operating system installed on it (CentOS 7/8, RedOS 7.2/7.3 or AlmaLinux 8). The node acts as a hypervisor and serves as an "execution point" for virtual machines.
A cluster is a group of nodes in the same location. The following can be defined within clusters:
- virtual machine allocation policies;
- high availability setting;
- network abstraction for SDN (IP-fabric or VxLAN).
HA (high availability) is an approach to the IT system, when the risk of incidents and damage from them is minimized, and the services work as continuously as possible.
An unbreakable cluster is what we call a high availability cluster in VMmanager.
Algorithm implementation details
To implement autonomous unbreakable clusters, the VMmanager team needed to solve the classic problem of achieving consensus in distributed systems. Therefore, we adapted the algorithm from the Paxos family to the specifics of the product.
The idea of the algorithm is that one of the nodes in such a cluster takes the role of leader and is able to make decisions at the level of the entire cluster. The algorithm ensures that there can be only one leader in the cluster at any given time.
In our case of algorithm implementation, two main factors are used to determine the availability of the node:
- connectivity at the control network level;
- connectivity at the network storage level.
An additional factor of determination is the verification IP address. It allows you to identify the situation when a node has lost connectivity with the control network, but the network for virtual machines is still available.
The corosync + kronosnet bundle is used to determine network-level availability and message exchange between nodes. Using the corosync messaging, the model ensures that all nodes receive messages sent in the same order.
Checks at the network storage level are used to determine the second factor of node availability. Nodes can store their metadata in the network storage, and keep track of cluster metadata. This data can only be managed by the current leader. Therefore, to activate high availability when using CEPH, the file system must be configured in the storage. When using a SAN storage, no additional settings are required.
When preparing a node for connection to a high availability cluster, the platform automatically installs and configures the daemon to synchronize the system clock.
The HA agent service, which is the VMmanager virtualization platform, is responsible for the collection, analysis, exchange of information and decision-making on the node side.
On the side of the platform master, these procedures are performed by the HA-watch microservice, which is responsible for the communication between the platform and the HA agent of the node. The HA agent, which is at that time the master, has the authority to decide on the recovery procedures in the event of an incident.
Activating high availability in a cluster
An important step in activating high availability in a cluster is the election of a leader. Election of a leader is initiated in the following situations:
- when high availability is first enabled on the cluster from the interface;
- when the current leader has failed;
- when changing the high availability configuration in the cluster;
- when upgrading components responsible for high availability in the cluster.
For a successful election, there must be at least N/2 + 1 electing nodes, where N is the total number of nodes in the cluster. For example, in a cluster of two nodes, both must be active, while in a cluster of 17 nodes, 9 will suffice. The algorithm ensures that the information about the sequence in which the nodes are ready is the same for all cluster members.
When selecting the leader, each of the electing nodes calculates its priority using the algorithm implemented in ha-agent, and communicates it to the rest of the cluster members. The node with the highest priority is selected as the leader. When all the priorities are known and all the electing nodes confirm that they have identified the leader, the cluster will start to work in high availability mode.
Nodes that were not ready at the beginning of the election will wait for the election to be completed and then join the cluster. As new nodes are added to a high availability cluster, they obey the existing leader.
If there are fewer serviceable nodes in the cluster than necessary, the election procedure will not start.
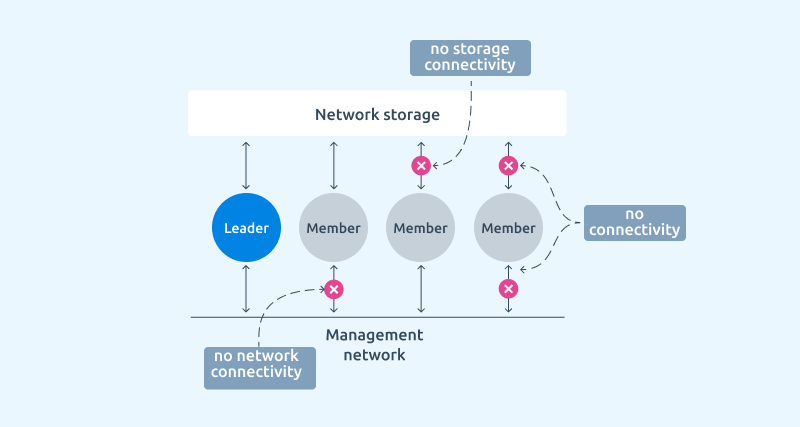
Statuses of nodes in the cluster
There are several statuses for the nodes in the cluster. They reflect the role or status of the server at the moment; these are the two "good" statuses:
- Leader. The node is the leader in its cluster.
- Member. The node is a simple member of a cluster.
And three statuses indicating an incident:
- Network isolation — the status reporting a network-related incident.
- Storage isolation — the status reporting a network data storage-related incident.
- Full failure. This status reflects that the node is completely unavailable.
In all incident situations, the platform starts the virtual infrastructure recovery procedures.
There are two additional statuses for nodes:
- Excluded from HA cluster. A node gets this status when it becomes unavailable via the network. However, this situation differs from the “no network connectivity” status in that the test IP address remains available for the node (it can be specified in the cluster settings). In this case, the platform does not start the virtual machine relocation procedure.
- Network unstable. The status is determined if the network is unavailable for less than 15 seconds and this occurs regularly. The node is now and again unavailable over the network. No recovery actions will be taken, but the platform will display this status for this node.
These statuses are not triggers to start the recovery procedure, but they inform the administrator about a node problem.
Recovery in a cluster
When a node detects one of its statuses, it stops all virtual machines and tries to inform the cluster leader about its status, but the leader is also able to determine that some of the nodes have passed to the incident status. After that, the procedure of virtual machines recovery starts according to the configured priorities.
In a high availability cluster, there are special rules for starting virtual machines after a node reboot. The virtual machine will only start if two conditions are met:
- the node must have a good status;
- the virtual machine must belong to only one node at a time.
The platform saves the information about the status of the node in the cluster metadata. This approach avoids cases of "split brain", when two virtual machines are connected to the same disk at the same time.
If a node goes to a bad status but cannot restart the virtual machines on its own, it will be rebooted by a system call from HA-agent or the daemon.
If a node fails, only virtual machines with the "High availability" parameter activated are restored. Therefore, the administrator must activate this parameter for virtual machines beforehand.
Timings are an important characteristic for assessing the continuity of business processes, because they determine the level of SLA. At this point, we have the following values:
- Leader selection time - no more than 15 seconds, provided there are enough electing nodes.
- Bad status recognition time - from 15 seconds, but no more than 1 minute (depending on the incident).
- Relocation time is a few seconds, as the disks of virtual machines are in the network storage.
- The duration of virtual machine downtime is made up of the time to recognize the bad status and the time to relocate and start the VM on the new node.
To activate high availability, the cluster must consist of at least two nodes, use a network storage (CEPH or SAN), and use KVM virtualization. Read more about cluster requirements in our documentation.
High availability of the platform
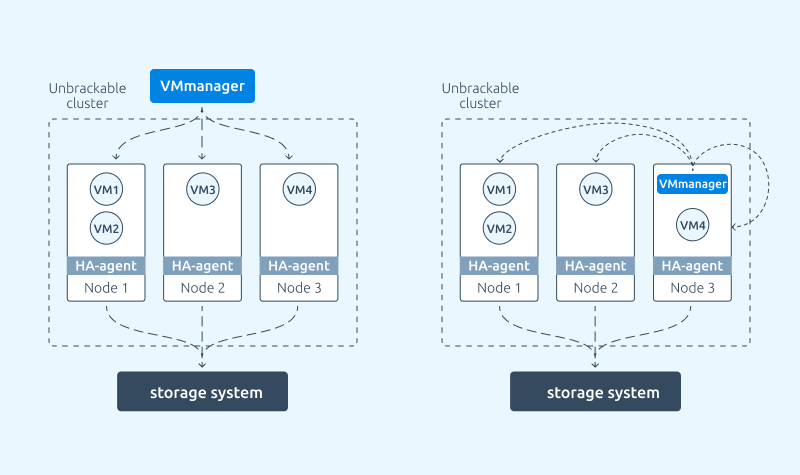
VMmanager is designed so that recovery procedures in each cluster are provided by HA agents and do not depend on the platform master. This means that failure of the server with VMmanager has no effect on high availability within clusters.
However, with an unbreakable cluster, you can ensure the stability of the VMmanager platform itself. For this purpose, a configuration is supported in which the platform master is migrated to one of the high availability virtual machines within the platform. So, in case of an incident on the server with the platform master, the autonomous unbreakable cluster will restore the virtual machine with VMmanager.
At present, you can set up such a configuration manually. In the future, this feature will appear in the platform settings and will only require a few clicks in the platform interface.
A little more about the plans
We will continue to develop the high availability functionality in VMmanager within the single ecosystem of ISPsystem products. In particular, we are planning to implement the concept of proactive high availability. It will be deployed in conjunction with our other product - the DCImanager equipment management platform. Proactive high availability will analyze the state of nodes at the equipment level in the data center and help predict its failure. After that, it will relocate important virtual machines to "healthy" nodes in advance.
Try autonomous unbreakable clusters in VMmanager for yourself and see how they work.