
In the era of phone over internet, artificial intelligence, and augmented reality, we are all used to having quick and easy access to the data we want or need, anytime and anywhere.
We want to be able to do so without needing to reach out to IT teams, understanding the complexities of technology, or constantly switching between platforms and systems. What we crave is called ‘data virtualization’.
To find out more about this all-important topic, and to better understand why it’s so vital to help you better serve both your staff and your customers, read our guide below.
Data Virtualization: A Definition
On a typical day, most businesses manage huge amounts of data, both structured and unstructured (much like in Hadoop). This data may be stored in a database, in a log file, a CRM system, or a whole host of other apps and platforms, and it can have various formats, including email, logs, and social media or web content.
How, then, can users visualize and modify the information they need, whenever they need to? With data virtualization. In a nutshell, data virtualization can be defined as a type of data management that enables users to access data – and modify it – whenever the need arises, and with no technical knowledge or details required. No matter what the data type is, how it is presented, or where it is stored: data virtualization simplifies and streamlines data access and handling.
Essentially, data virtualization allows us to centralize and simplify data access from a myriad of sources without the need to copy or move the data itself. The result? Quicker, simpler, and more convenient access to data.
As might already be apparent, the benefits of data virtualization are numerous, and we will soon discuss them in detail. But first, let’s try to gain a better understanding of how data virtualization works in practice.
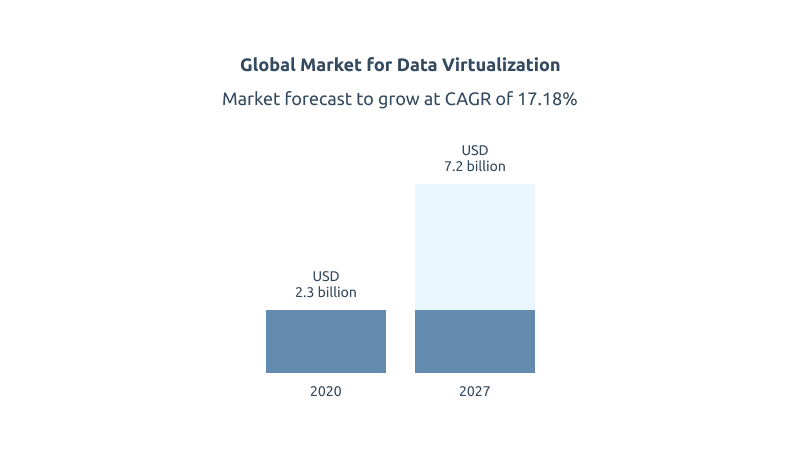
Data Virtualization at Work
To begin with, it’s important to clarify that data virtualization occurs via middleware. This simply means that it happens through a single layer that allows virtual access to data and that sits on top of several data sources.
Therefore before starting with data virtualization, a business must select a middleware that is suited to its specific needs, and that can scale easily across its infrastructure – whether it be cloud, on-premise, or hybrid.
The layer that you have chosen to use will then display any type of information as a unified virtual view. Of course, this all takes place in real time and whenever a user triggers the process.
But what does the data virtualization architecture look like, exactly? Generally speaking, a virtualization structure is formed of three building blocks, called a connection layer, an abstraction layer, and a consumption layer.
The connection layer includes all the tools that enable it to connect to data sources on-the-fly. The abstraction layer features all the services needed to display, handle, and utilize logical views of the data. Lastly, the consumption layer comprises all the tools and apps needed to access and consume abstract data.
Once this structure has been put into place, users can quickly and easily find the data they want through data catalogs or through API (application programming interfaces) systems. For example, if you want to create a report by pulling specific data from a data source, virtualization helps you to achieve this in real time.
At this point, you might be wondering: is data virtualization safe from a cybersecurity point of view? The answer is ‘yes’. Simply ensure that you have established specific privacy and security SLAs (service level agreements) and that you meet your industry’s rules and regulations, and you can use data virtualization safely and securely.
The Benefits of Data Virtualization
You might already know the benefits of agile, but do you know what incredible advantages data virtualization can generate for your business? If not, and if you are keen to find out, read the next section.
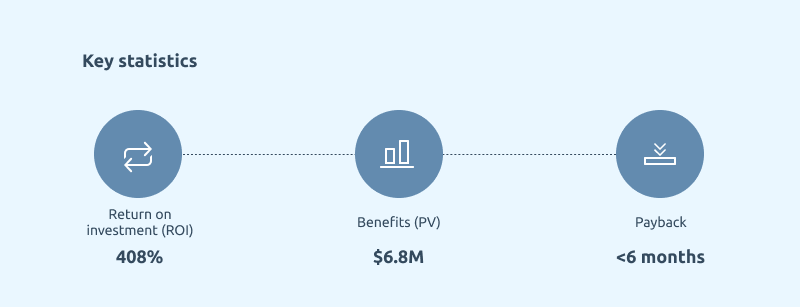
1. Faster, and More Accurate, Analytics
Data virtualization enables real-time, remote access to any data type, model, and source. As a result you can run your analytics processes ultra-quickly. As we mentioned, one of the advantages of data virtualization is the fact that it does not require any coding or technical knowledge, allowing you to simply focus on the task at hand: analytics and decision-making processes.
2. Enhanced Simplicity and Flexibility
The centralization that data virtualization provides translates into higher simplicity and flexibility for business users seeking to access and modify data at the touch of a button. Data virtualization interfaces are also generally user-friendly and intuitive, further enhancing usability from non-technical teams.
3. Increased Cost-Effectiveness
All businesses are constantly seeking to implement solutions that enable them to save money while boosting productivity. And this is exactly what a data virtualization environment can help you achieve.
With data virtualization, your business won’t need to purchase any extra tools or add any physical components to its infrastructure. This, in turn, translates into lower costs related to:
- Not needing to undergo a complex and costly restructuring of your front-end systems.
- Being able to use and integrate your existing systems with the middleware that you have selected for your data virtualization.
- Using one single point of data access as opposed to several different ways to access data across your company’s departments.
- Defining KPIs and rules in a central way, which allows for easier and more secure management of critical metrics.
- Identifying and resolving potential errors or problems rapidly.
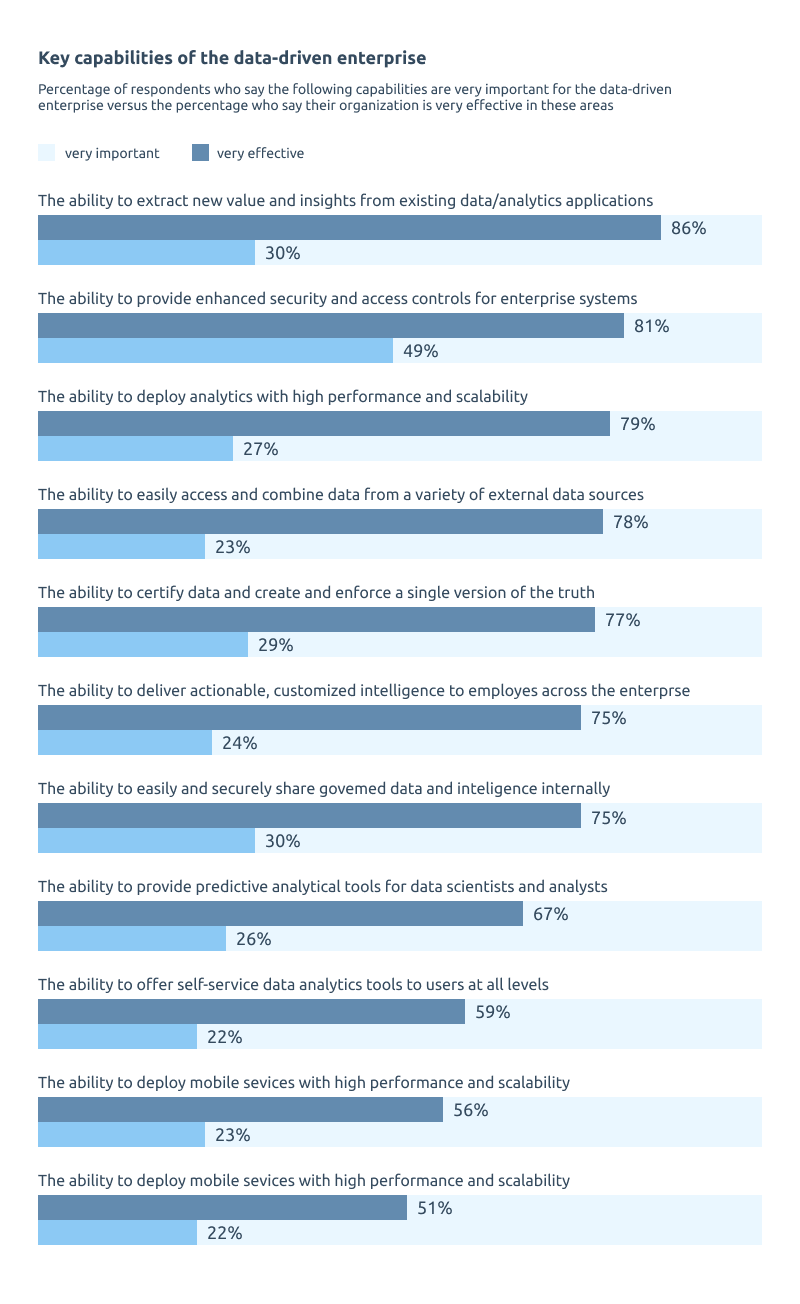
Some Practical Use Cases
Businesses harness the power of data virtualization, and reap its great benefits, in a myriad of ways. Let’s now take a look at what the main practical use cases for data virtualization are, which will help you to better understand why this practice is so important for all businesses.
Integrating Data
If you have only just started using data virtualization, then this is probably the most common type of use that you and your team are going to encounter. The chances are, in fact, that your company accesses data from a plethora of disparate sources.
With data virtualization, you can connect an old data source – hosted in a client/server setup – with a brand new digital platform. Once all these connections are established, your users can rapidly access, view, and manage the data they need, whenever they need it.
Big Data and Analytics
Another very popular data virtualization use case revolves around analytics. Because data virtualization lets you access virtually limitless amounts of data coming from the most disparate data sources that you can think of, you can then perform analytics activities easily and rapidly.
Siloed Data Access
Does your company require different systems or applications for the different services it provides? Maybe, you run Apache hive on top of several different databases? If so, you might be familiar with the frustration of having to request access to all these separate systems whenever you, or a team member, require a specific type of information.
This annoyance disappears with data virtualization. Because virtualization works across siloed data, it lets everyone across your company enjoy a single point of access for all the data they need.
Abstraction and Decoupling
While data virtualization enables your staff to access and manage data across different apps, platforms, and systems, it also provides a high level of security and privacy. What if, for example, you want to isolate a specific data source because of compliance or privacy reasons?
Data virtualization allows you to do so, which in turn prevents certain users from accessing the data that you have isolated.
ERP Upgrades
If your team gets constant headaches whenever you need to run an ERP upgrade, then data virtualization can come to the rescue. Most ERP projects are notoriously lengthy and complicated, resulting in frustration and extra work for your teams. With data virtualization, however, your ERP teams can become much more efficient and work faster, decrease the TCO (total cost of ownership), and eliminate the typical complexities that an ERP project often involves.
Data Virtualization: The Best Way to Access and Manage Data Across Your Business
Being able to allow easy, rapid, and secure data access to your team whenever and wherever they need is paramount if you want to run efficient and productive business operations. With data virtualization, you can achieve just that.
Thanks to its centralized and real-time access to all types of data from several different sources, data virtualization allows business users to cut costs, simplify processes, and run better and more timely analytics.